열거형 (Enum)
열거형 이란?
서로 연관된 상수들의 집함을 의미한다.
상수란 변하지 않는 값을 의미하며 final 키워드를 사용하여 선언할 수있다.
열거형은 이러한 상수들을 보다 간편하게 관리할 때 유용하게 사용할 수 있는 자바의 문법 요소이며, 주로 몇가지로 한정된 변하지 않는 데이터를 다루는 데 사용한다.
자바에서 열거형은 여러 상수들을 보다 편리하게 선언하고 관리할 수 있게 하며, 상수 명의 중복을 피하고, 타입에 대한 안정성을 보장한다.
열거형을 사용할 때는 다음과 같이 코드 블록 안에 선언하고자 하는 상수의 이름을 나열하기만 하면된다.
enum 열거형이름 { 상수명1, 상수명2, 상수명3, ...}사계절을 예로 들어보자. enum을 사용하여 사계절을 상수로 정의하면 다음과 같다.
enum Seasons {
SPRING, //정수값 0 할당
SUMMER, //정수값 1 할당
FALL, //정수값 2 할당
WINTER //정수값 3 할당
}참고로, 상수는 대소문자로 모두 작성이 가능하지만, 과례적으로 대문자로 작성한다.
또한 각각의 열거 상수들은 객체이기 때문에, 위의 예시에서 Seasons라는 이름의 열거형은 SPRING, SUMMER, FALL, WINTER는 총 네 개의 열거 객체를 포함하고 있다고 말할 수 있다.
마지막으로 각각의 상수들에는 따로 값을 지정해주지 않아도 자동적으로 0부터 시작하는 정수값이 할당되어 각각의 상수를 가리키게 된다.
이렇게 선언한 열거형을 사용하는 아래 예시를 살펴보자.
enum Seasons { SPRING, SUMMER, FALL, WINTER }
public class EnumExample {
public static void main(String[] args) {
System.out.println(Seasons.SPRING); // SPRING
}
}열거형에 선언된 상수에 접근하는 방법은 열거형이름.상수명 을 통해서 가능하다. 앞서 배웠던 클래스에서 static 변수를 참조하는 것과 동일하다고 할 수 있다.
내가 가장 좋아하는 계절이라는 의미의 참조 변수 favoriteSeason에 Seasons.SPRING을 담아보자.
enum Seasons { SPRING, SUMMER, FALL, WINTER }
public class EnumExample {
public static void main(String[] args) {
Seasons favoriteSeason = Seasons.SPRING;
System.out.println(favoriteSeason); // SPRING
}Seasons.SPRING을 Seasons 타입의 참조 변수에 할당하고 있다.
비슷한 예제를 하나 더 살펴보자.
enum Level {
LOW, // 0
MEDIUM, // 1
HIGH // 2
}
public class Main {
public static void main(String[] args) {
Level level = Level.MEDIUM;
switch(level) {
case LOW:
System.out.println("낮은 레벨");
break;
case MEDIUM:
System.out.println("중간 레벨");
break;
case HIGH:
System.out.println("높은 레벨");
break;
}
}
}
//출력값
중간 레벨위의 코드예제를 보면, Level이라는 열거형을 하나 만들고, 그 안에 세 가지의 열거 상수(LOW, MEDIUM, HIGH)를 선언해 주었다.
그리고 열거형과 같은 타입의 참조 변수 level에 Level.MEDIUM 값을 할당하고 switch문을 통해 해당 값에 대한 출력값을 얻을 수 있었다.
이처럼 enum을 사용하면 변경되지 않는 한정적인 데이터들을 효과적으로 관리할 수 있다.
마지막으로 열거형에서 사용할 수 있는 메서드를 살펴보자.
아래 메서드들은 모든 열거형의 조상인 java.lang.Enum 에 정의되어 있는 것으로, 클래스에서 최상위 클래스 Object에 정의된 메서드들을 사용할 수 있었던 것과 동일하다고 할 수 있다.
| 리턴 타입 |
메서드(매개변수) | 설명 |
| String | name() | 열거 객체가 가지고 있는 문자열을 리턴하며, 리턴되는 문자열은 열거타입을 정의할 때 사용한 상수 이름과 동일합니다. |
| int | ordinal() | 열거 객체의 순번(0부터 시작)을 리턴합니다. |
| int | compareTo(비교값) | 주어진 매개 값과 비교해서 순번 차이를 리턴합니다. |
| 열거 타입 | valueOf(String name) | 주어진 문자열의 열거 객체를 리턴합니다. |
| 열거 배열 | values() | 모든 열거 객체들을 배열로 리턴합니다. |
위의 코드를 사용한 예제를 살펴보자.
enum Level {
LOW, // 0
MEDIUM, // 1
HIGH // 2
}
public class EnumTest {
public static void main(String[] args) {
Level level = Level.MEDIUM;
Level[] allLevels = Level.values();
for(Level x : allLevels) {
System.out.printf("%s=%d%n", x.name(), x.ordinal());
}
Level findLevel = Level.valueOf("LOW");
System.out.println(findLevel);
System.out.println(Level.LOW == Level.valueOf("LOW"));
switch(level) {
case LOW:
System.out.println("낮은 레벨");
break;
case MEDIUM:
System.out.println("중간 레벨");
break;
case HIGH:
System.out.println("높은 레벨");
break;
}
}
}
//출력값
LOW=0
MEDIUM=1
HIGH=2
LOW
true
중간 레벨
제네릭
제네릭이란?
자바에서 제네릭이란, 클래스나 메서드의 코드를 작성할 때, 타입을 구체적으로 지정하는 것이 아니라, 추후에 지정할 수 있도록 일반화해 두는 것을 의미한다. 즉, 작성한 클래스 또는 메서드의 코드가 특정 데이터 타입에 얽매이지 않게 해 둔 것을 의미한다.
제네릭을 사용하면 단 하나의 클래스 만으로 모든 타입의 데이터를 저장할 수 있는 인스턴스를 만둘 수 있다.
class Basket<T> {
private T item;
public Basket(T item) {
this.item = item;
}
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}위의 Basket 클래스는 다음과 같이 인스턴스화할 수 있다.
Basket<String> basket1 = new Basket<String>("기타 줄");Basket 클래스가 인스턴스화될 때 클래스 이름 뒤에 <String>이 따라붙고 있다. 이 또한 제네릭의 문법으로, 아래와 같은 의미로 간주할 수 있다.
"Basket 클래스 내의 T를 String으로 바꿔라"
위 코드를 실행하면 Basket 클래스 내부의 T가 모두 String으로 치환되는 것처럼 동작하게 된다.
class Basket {
private String item;
Basket(String item) {
this.item = item;
}
public String getItem() {
return item;
}
public void setItem(String item) {
this.item = item;
}
}아래와 같이 <> 안에 Integer를 넣어 인스턴스화한다면 Basket 클래스 내부의 T는 모두 Integer로 치환된다.
Basket<Integer> basket2 = new Basket<Integer>(1);
// 위와 같이 인스턴스화하면 Basket 클래스는 아래와 같이 변환됩니다.
class Basket<Integer> {
private Integer item;
public Basket(Integer item) {
this.item = item;
}
public Integer getItem() {
return item;
}
public void setItem(Integer item) {
this.item = item;
}
}
제네릭이 사용된 클래스를 제네릭 클래스라고 한다. 앞서 익히 살펴보았던 Basket 클래스가 바로 제네릭 클래스이다.
class Basket<T> {
private T item;
public Basket(T item) {
this.item = item;
}
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}위의 코드에서, T를 타입 매개변수라고 하며, <T>와 같이 꺾쇠 안에 넣어 클래스 이름 옆에 작성해 줌으로써 클래스 내부에서 사용할 타입 매개변수를 선언할 수 있다.
즉, 아래와 같이 타입 매개 변수 T를 선언하면,
class Basket<T> {
}클래스 몸체에서 T를 임의의 타입으로 사용할 수 있다.
class Basket<T> {
private T item;
...
}만약, 타입 매개변수를 여러 개 사용해야 한다면, 아래와 같이 선언하면 된다.
class Basket<K, V> { ... }타입 매개변수는 임의의 문자로 지정할 수 있다. 위에서 사용한 T, K, V는 각각 Type, Key, Value의 첫 글자를 따온 것이다. 이 외에도, Element를 뜻하는 E, Number를 뜻하는 N, 그리고 Result를 뜻하는 R도 자주 사용된다.
제네릭 클래스를 정의할 때 주의할 점
제네릭 클래스에서 타입 매개변수를 임의의 타입으로 사용할 수 있다고 하였습니다. 이때, 아래와 같이 클래스 변수에는 타입 매개변수를 사용할 수 없습니다.
class Basket<T> {
private T item1; // O
static T item2; // X
}클래스 변수에 타입 매개변수를 사용할 수 없는 이유는 클래스 변수의 특성을 생각해 보면 충분히 이해할 수 있습니다. 클래스 변수는 모든 인스턴스가 공유하는 변수입니다. 만약, 클래스 변수에 타입 매개변수를 사용할 수 있다면 클래스 변수의 타입이 인스턴스 별로 달라지게 됩니다.
즉, 클래스 변수에 타입 매개변수를 사용할 수 있다면, Basket<String>으로 만든 인스턴스와, Basket<Integer>로 만든 인스턴스가 공유하는 클래스 변수의 타입이 서로 달라지게 되어, 클래스 변수를 통해 같은 변수를 공유하는 것이 아니게 됩니다. 따라서 static이 붙은 변수 또는 메서드에는 타입 매개변수를 사용할 수 없습니다.
제네릭 클래스 사용
제네릭 클래스는 멤버를 구성하는 코드에 특정한 타입이 지정되지 않은 클래스이므로, 제네릭 클래스를 인스턴스화할 때에는 의도하고자 하는 타입을 아래와 같이 지정해주어야 합니다.
단, 타입 매개변수에 치환될 타입으로 기본 타입을 지정할 수 없습니다. 만약, int, double과 같은 원시 타입을 지정해야 하는 맥락에서는 Integer, Double과 같은 래퍼 클래스를 활용합니다.
Basket<String> basket1 = new Basket<String>("Hello");
Basket<Integer> basket2 = new Basket<Integer>(10);
Basket<Double> basket3 = new Basket<Double>(3.14);위의 코드에서 new Basket<…>은 아래와 같이 구체적인 타입을 생략하고 작성해도 됩니다. 참조변수의 타입으로부터 유추할 수 있기 때문입니다.
Basket<String> basket1 = new Basket<>("Hello");
Basket<Integer> basket2 = new Basket<>(10);
Basket<Double> basket2 = new Basket<>(3.14);
마지막으로, 제네릭 클래스를 사용할 때에도 다형성을 적용할 수 있습니다.
class Flower { ... }
class Rose extends Flower { ... }
class RosePasta { ... }
class Basket<T> {
private T item;
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}
class Main {
public static void main(String[] args) {
Basket<Flower> flowerBasket = new Basket<>();
flowerBasket.setItem(new Rose()); // 다형성 적용
flowerBasket.setItem(new RosePasta()); // 에러
}
}new Rose()를 통해 생성된 인스턴스는 Rose 타입이며, Rose 클래스는 Flower 클래스를 상속받고 있으므로, Basket<Flower>의 item에 할당될 수 있습니다. Basket<Flower>은 결국 item의 타입을 Flower로 지정하는 것이고, Flower 클래스는 Rose 클래스의 상위 클래스이기 때문입니다.
반면, new RosePasta()를 통해 생성된 인스턴스는 RosePasta 타입이며, RosePasta 클래스는 Flower 클래스와 아무런 관계가 없습니다. 따라서, flowerBasket의 item에 할당될 수 없습니다.
제한된 제네릭 클래스
앞서 살펴본 예제의 Basket 클래스는 인스턴스화할 때 어떠한 타입도 지정해 줄 수 있습니다.
즉, 타입을 지정하는 데에 있어 제한이 없습니다.
class Flower { ... }
class Rose extends Flower { ... }
class RosePasta { ... }
// 제네릭 클래스 정의
class Basket<T> {
private T item;
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}
class Main {
public static void main(String[] args) {
// 인스턴스화
Basket<Rose> roseBasket = new Basket<>();
Basket<RosePasta> rosePastaBasket = new Basket<>();
}
}그러나, 타입 매개변수를 선언할 때 아래와 같이 코드를 작성해 주면 Basket 클래스를 인스턴스화할 때 타입으로 Flower 클래스의 하위 클래스만 지정하도록 제한됩니다.
class Flower { ... }
class Rose extends Flower { ... }
class RosePasta { ... }
class Basket<T extends Flower> {
private T item;
...
}
class Main {
public static void main(String[] args) {
// 인스턴스화
Basket<Rose> roseBasket = new Basket<>();
Basket<RosePasta> rosePastaBasket = new Basket<>(); // 에러
}
}이와 같이 특정 클래스를 상속받은 클래스만 타입으로 지정할 수 있도록 제한하는 것뿐만 아니라, 특정 인터페이스를 구현한 클래스만 타입으로 지정할 수 있도록 제한할 수도 있습니다. 이 경우에도 동일하게 extends 키워드를 사용합니다.
interface Plant { ... }
class Flower implements Plant { ... }
class Rose extends Flower implements Plant { ... }
class Basket<T extends Plant> {
private T item;
...
}
class Main {
public static void main(String[] args) {
// 인스턴스화
Basket<Flower> flowerBasket = new Basket<>();
Basket<Rose> roseBasket = new Basket<>();
}
}만약, 특정 클래스를 상속받으면서 동시에 특정 인터페이스를 구현한 클래스만 타입으로 지정할 수 있도록 제한하려면 아래와 같이 &를 사용하여 코드를 작성해 주면 됩니다.
다만, 이러한 경우에는 클래스를 인터페이스보다 앞에 위치시켜야 합니다. 아래 예제의 (1)을 참고하세요.
interface Plant { ... }
class Flower implements Plant { ... }
class Rose extends Flower implements Plant { ... }
class Basket<T extends Flower & Plant> { // (1)
private T item;
...
}
class Main {
public static void main(String[] args) {
// 인스턴스화
Basket<Flower> flowerBasket = new Basket<>();
Basket<Rose> roseBasket = new Basket<>();
}
}
제네릭 메서드
클래스 전체를 제네릭으로 선언할 수도 있지만, 클래스 내부의 특정 메서드만 제네릭으로 선언할 수 있다. 이를 제네릭 메서드라고 한다.
제네릭 메서드의 타입 매개 변수 선언은 반환타입 앞에서 이루어지며, 해당 메서드 내에서만 선언한 타입 매개 변수를 사용할 수 있다.
class Basket {
...
public <T> void add(T element) {
...
}
}제네릭 메서드의 타입 매개 변수는 제네릭 클래스의 타입 매개 변수와 별개의 것이다.
즉, 아래와 같이 동일하게 T라는 타입 매개 변수명을 사용한다고 하더라도, 같은 알파벳 문자를 이름으로 사용하는 것일 뿐, 서로 다른 타입 매개 변수로 간주된다.
class Basket<T> { // 1 : 여기에서 선언한 타입 매개 변수 T와
...
public <T> void add(T element) {// 2 : 여기에서 선언한 타입 매개 변수 T는 서로 다른 것이다.
...
}
}이는 타입이 지정되는 시점이 서로 다르기 때문이다.
즉, 클래스명 옆에서 선언한 타입 매개 변수는 클래스가 인스턴스화될 때 타입이 지정된다.
그러나, 제네릭 메서드의 타입 지정은 메서드가 호출될 때 이루어진다. 제네릭 메서드를 호출할 때에는 아래와 같이 호출 하며, 이때 제네릭 메서드에서 선언한 타입 매개 변수의 구체적인 타입이 지정된다.
Basket<String> basket = new Bakset<>(); // 위 예제의 1의 T가 String으로 지정됩니다.
basket.<Integer>add(10); // 위 예제의 2의 T가 Integer로 지정됩니다.
basket.add(10); // 타입 지정을 생략할 수도 있습니다.또한, 클래스 타입 매개 변수와 달리 메서드 타입 매개 변수는 static 메서드에서도 선언하여 사용할 수 있다.
class Basket {
...
static <T> int setPrice(T element) {
...
}
}제네릭 메서드는 메서드가 호출되는 시점에서 제네릭 타입이 결정되므로, 제네릭 메서드를 정의하는 시점에서 실제 어떤 타입이 입력되는지 알 수 없다. 따라서 length()와 같은 String 클래스의 메서드는 제네릭 메서드를 정의하는 시점에 사용할 수 없다.
class Basket {
public <T> void print(T item) {
System.out.println(item.length()); // 불가
}
}하지만 모든 자바 클래스의 최상위 클래스인 Object 클래스의 메서드는 사용 가능하다. 모든 클래스는 Object 클래스를 상속받기 때문이다. 지금까지 사용해 본 equals(), toString()등이 Object 클래스의 메서드에 속한다.
class Basket {
public <T> void getPrint(T item) {
System.out.println(item.equals("Kim coding")); // 가능
}
}
와일드카드
와일드카드란?
자바의 제네릭에서 와일드 카드는 어떠한 타입으로든 대체될 수 있는 타입 파라미터를 의미하며, 기호 ? 로 와일드ㅜ 카드를 사용할 수 있다. 일반적으로 와일드 카드는 extends 와 super 키워드를 조합하여 사용한다.
<? extends T>
<? super T><? extends T>는 와일드카드에 상한 제한을 두는 것으로서, T와 T를 상속받는 하위 클래스 타입만 타입 파라미터로 받을 수 있도록 지정한다.
반면, <? super T>는 와일드카드에 하한 제한을 두는 것으로, T와 T의 상위 클래스만 타입 파라미터로 받도록 한다.
참고로, extends 및 super 키워드와 조합하지 않은 와일드카드(<?>)는 <? extends Object>와 같다. 즉, 모든 클래스 타입은 Object 클래스를 상속받으므로, 모든 클래스 타입을 타입 파라미터로 받을 수 있음을 의미한다.
예외 처리
예외 처리란?
예기치 않게 발생하는 에러에 대응할 수 있는 코드를 미리 사전에 작성하여 프로그램의 비정상적인 종료를 방지하고, 정상적인 실행 상태를 유지하기 위한 방법이다.
컴퓨터 프로그래밍에서 에러가 발생하는 원인은 수없이 다양하다.
몇 가지 예를 들어보면 아래와 같다.
- 사용자의 입력 오류
- 네트워크 연결 끊김
- 디스크 메모리 공간 부족 등 물리적 한계
- 개발자의 코드 에러
- 존재하지(유효하지) 않는 파일 불러오기
위의 원인들을 다시 내부적인 요인과 외부적인 요인으로 구분할 수 있다.
대표적인 외부 요인으로는 하드웨어의 문제, 네트워크의 연결 끊김, 사용자 조작 오류 등이있다.
대표적인 내부 요인으로는 개발자의 코드 작성 에러를 언급할 수 있다.
개발자가 프로그래밍 하면서 발생시키기 쉬운 대표적인 오류를 몇 가지만 살펴보자.
아래의 코드 예제는 존재하지 않는 파일을 실행하고자 시도하고 있다.
public class ErrorTest {
public static void main(String[] args) {
BufferedReader notExist = new BufferedReader(new FileReader("없는 파일"));
notExist.readLine();
notExist.close();
}
}아마 인텔리제이에서 실행하게 되면 코드가 실행되기도 전에 IDE가 빨간 줄로 무언가 잘못되었음을 표시해 주는 모습을 확인할 수 있을 것이다.
실제로 코드를 실행하면 다음과 유사한 에러 메시지를 확인할 수 있다.
java: unreported exception java.io.FileNotFoundException; must be caught or declared to be thrownFileNotFoundException이라는 이름에서 확인할 수 있는 것처럼, 실제로 존재하지 않는 파일을 불러오려 시도할 때 발생하는 예외이다.
이번엔 아래의 코드를 실행해보자.
public class ErrorTest {
public static void main(String[] args) {
int[] array = {2,4,6};
System.out.println(array[3]);
}
}위의 코드예제는 배열의 범위 밖에 있는 값을 불러오고자 시도했다. 그리고 해당 코드를 실행하면, 아래와 같은 에러가 발생한다.
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: Index 3 out of bounds for length 3
at ErrorTest.main(ErrorTest.java:4)이 에러는 ArrayIndexOutOfBoundsException이라는 이름에서 어렵지 않게 유추할 수 있듯이 배열의 범위를 벗어난 값을 불러오고자 시도할 때 발생하는 예외이다.
대부분의 경우는 이렇게 에러 메세지를 확인하면 에러가 발생한 이유를 어렵지 않게 유추해볼 수 있다.
컴파일 에러
컴파일 에러는 이름 그대로 "컴파일할 때" 발생하는 에러를 가리킨다.
주로 세미콜론 생략, 오타, 잘못된 자료형, 잘못된 포맷 등 문법적인 문제를 가리키는 신택스(syntax)오류로부터 발생하기 때문에 신택스 에러(Systax Errors)라고 부르기도 한다.
컴파일 에러는 자바 컴파일러가 오류를 감지하여, 사용자에게 친절하게 알려주기 때문에 상대적으로 쉽게 발견하고 수정할 수 있다. 이렇게 친절하고 쉽게 발견할 수 있어 개발자들 사이에서 "가장 좋은 에러는 컴파일 에러다"라는 말이 있을 정도다.
컴파일 에러 코드 예제를 하나 더 살펴보자
public class ErrorTest {
public static void main(String[] args) {
int i;
for (i= 1; i<= 5; i++ {
System.out.println(i);
}
}
}위 코드예제는 for문의 조건 설정 영역에서 괄호 ')' 가 빠진 에러였다. 해당 코드를 실행하면 아래와 같은 문구가 나오게 된다. 이처럼 컴파일 에러는 상대적으로 발견도 쉽고, 해결도 어렵지 않다.
java: ')' expected
런타임 에러
런타임에러는 코드를 실행하는 과정 런타임 시에 발생하는 에러를 말한다.
즉, 프로그램이 실행될 때 만나게 되는 에러이다.
아래의 코드 예시를 살펴보자
public class RuntimeErrorTest {
public static void main(String[] args) {
System.out.println(4 * 4);
System.out.println(4 / 0); // 예외 발생
}
}
//출력값
16
Exception in thread "main" java.lang.ArithmeticException: / by zero
at RuntimeErrorTest.main(RuntimeErrorTest.java:5)위의 코드 예제는 겉으로 보기에는 아무런 문제가 없는 듯 보인다.
하지만 위의 코드를 실행하면, ArithmeticException 예외가 발생한다.
참고로 , ArithmeticException은 특정 숫자를 0 으로 나눴을 때 발생하는 예외이다.
에러와 예외
자바에서는 코드 실행(run-time) 시 잠재적으로 발생할 수 있는 프로그램 오류를 크게 에러(error)와 예외(exception)으로 구분하고 있다.
에러란 한번 발생하면 복구하기 어려운 수준의 심각한 오류를 의미하고, 대표적으로 메모리 부족(OutOfMemoryError)과 스택오버플로우(StackOverflowError) 등이 있다.
반면 예외는 잘못된 사용 또는 코딩으로 인한 상대적으로 미약한 수준의 오류로서 코드 수정 등을 통해 수습이 가능한 오류를 지칭한다.
예외 클래스의 상속 계층도
자바에서는 예외가 발생하면 예외 클래스로부터 객체를 생성하여 해당 인스턴스를 통해 예외 처리를 한다.
자바의 모든 에러와 예외 클래스는 Throwable 클래스로부터 확장되며, 모든 예외의 최고 상위 클래스는 Exception 클래스다.
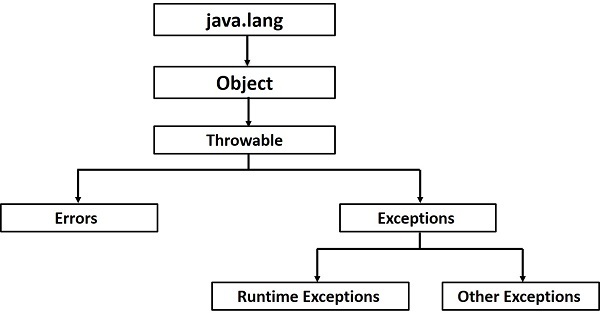
모든 예외의 최고 상위 클래스인 Exception 클래스는 다시 크게 일반 예외 클래스와 실행 예외 클래스로 나눌 수 있다.
일반 예외 클래스(Exception)
- 런타임 시 발생하는 RuntimeException 클래스와 그 하위 클래스를 제외한 모든 Exception 클래스와 그 하위 클래스들을 가리킨다.
- 컴파일러가 코드 실행 전에 예외 처리 코드 여부를 검사한다고 하여 checked 예외라 부르기도 한다.
- 주로 잘못된 클래스명(ClassNotFoundException)이나 데이터 형식(DataFormatException) 등 사용자편의 실수로 발생하는 경우가 많다.
실행 예외 클래스(Runtime Exception)
- 앞서 언급한 런타임 시 발생하는 RuntimeException 클래스와 그 하위클래스를 지칭한다.
- 컴파일러가 예외 처리 코드 여부를 검사하지 않는다는 의미에서 unchecked 예외라 부르기도 한다.
- 주로 개발자의 실수로 발생하는 경우가 많고, 자바 문법 요소와 관련이 있다.
- 클래스 간 형변환 오류(ClassCastException), 벗어난 배열 범위 지정(ArrayIndexOutOfBoundsException), 값이 null인 참조변수 사용(NullPointerException) 등이 있다.
try - catch문
예외 처리란 잠재적으로 발생할 수 있는 비정상 종료나 오류에 대비하여 정상 실행을 유지할 수 있도록 처리하는 코드 작성 과정을 의미한다. 자바에서 예외 처리는 try - catch 블록을 통해 구현할 수 있다.
기본적인 구조는 다음과 같다.
try {
// 예외가 발생할 가능성이 있는 코드를 삽입
}
catch (ExceptionType1 e1) {
// ExceptionType1 유형의 예외 발생 시 실행할 코드
}
catch (ExceptionType2 e2) {
// ExceptionType2 유형의 예외 발생 시 실행할 코드
}
finally {
// finally 블록은 옵셔널
// 예외 발생 여부와 상관없이 항상 실행
}먼저, try 블록 안에 예외가 발생할 가능성이 있는 코드를 삽입한다.
만약 작성한 코드가 예외 없이 정상적으로 실행되면 아래 catch 블록은 실행되지 않고 finally 블록이 실행된다.
finally 블록은 옵션으로 필수적으로 포함되지 않아도 되지만, 만약 포함될 때는 예외 발생 여부와 상관없이 항상 실행되게 된다.
catch 블록은 예외가 발생할 때 실행되는 코드로, 여러 종류의 예외를 처리할 수 있다.
모든 예외를 받을 수 있는 Exception 클래스 하나로 처리도 가능하며, 각기 다른 예외를 하나 이상의 catch 블록을 사용하여 처리할 수 있다.
만약, catch 블록이 여러 개인 경우, 일치하는 하나의 catch 블록만이 실행되고 예외처리 코드가 종료되거나 finally 블록으로 넘어가게 된다.
일치하는 블록을 찾지 못할 때는 예외는 처리되지 못한다.
아래의 코드 예제를 통해 살펴보자
public class RuntimeExceptionTest {
public static void main(String[] args) {
System.out.println("[소문자 알파벳을 대문자로 출력하는 프로그램]");
printMyName("abc"); // (1)
printMyName(null); // (2) 넘겨주는 매개변수가 null인 경우 NullPointerException 발생
System.out.println("[프로그램 종료]");
}
static void printMyName(String str) {
String upperCaseAlphabet = str.toUpperCase();
System.out.println(upperCaseAlphabet);
}
}
//출력값
[소문자 알파벳을 대문자로 출력하는 프로그램]
ABC //(3) 정상 실행
Exception in thread "main" java.lang.NullPointerException // (4) 예외 발생!
at RuntimeExceptionTest.printMyName(RuntimeExceptionTest.java:11)
at RuntimeExceptionTest.main(RuntimeExceptionTest.java:6)위의 코드는 소문자 알파벳을 대문자로 바꿔주는 간단한 프로그램 코드이다.
printMyName 메서드를 먼저 확인해보면, 문자열 타입의 매개변수 str을 받아 대문자로 변환해 준 다음 해당 문자열을 출력하고 있다.
이러한 순서에 따라 (1)번 코드 라인에서 printMyName 메서드를 호출하면, 출력값 (3)번의 결과를 확인할 수 있다.
하지만 (2)번의 코드라인은 매개변수 값을 null값으로 넘겨주기 때문에 해당 메서드가 호출 되면 출력값 (4)번처럼 NullPointerException 예외가 발생하게 된다.
이제 이 예제를 try - catch 문을 사용해 예외 처리 해보자.
public class RuntimeExceptionTest {
public static void main(String[] args) {
try {
System.out.println("[소문자 알파벳을 대문자로 출력하는 프로그램]");
printMyName(null); // (1) 예외 발생
printMyName("abc"); // 이 코드는 실행되지 않고 catch 문으로 이동
}
catch (ArithmeticException e) {
System.out.println("ArithmeticException 발생!"); // (2) 첫 번째 catch문
}
catch (NullPointerException e) { // (3) 두 번째 catch문
System.out.println("NullPointerException 발생!");
System.out.println("e.getMessage: " + e.getMessage()); // (4) 예외 정보를 얻는 방법 - 1
System.out.println("e.toString: " + e.toString()); // (4) 예외 정보를 얻는 방법 - 2
e.printStackTrace(); // (4) 예외 정보를 얻는 방법 - 3
}
finally {
System.out.println("[프로그램 종료]"); // (5) finally문
}
}
static void printMyName(String str) {
String upperCaseAlphabet = str.toUpperCase();
System.out.println(upperCaseAlphabet);
}
}
// 출력값
[소문자 알파벳을 대문자로 출력하는 프로그램]
NullPointerException 발생!
e.getMessage: null
e.toString: java.lang.NullPointerException
[프로그램 종료]
java.lang.NullPointerException
at RuntimeExceptionTest.printMyName(RuntimeExceptionTest.java:20)
at RuntimeExceptionTest.main(RuntimeExceptionTest.java:7)
(1) 예외 발생
먼저, try 문 안에서 순차적으로 잘 실행되는 코드가 null 값을 매개변수로 넘긴 printMyName 메서드가 호출되는 부분에서 예외가 발생했습니다.
따라서 다음 코드 라인인 printMyName("abc")는 호출되지 않고 예외가 발생한 시점에 catch 문으로 넘어갑니다.
(2) 첫 번째 catch문
발생한 예외가 NullPointerException인데, 첫 번째 catch 문에서 조건으로 받는 예외는 ArithmeticException이므로 예외처리가 되지 않고 그냥 지나갑니다.
참고로 이때 검사는 instanceOf 연산자를 통해 생성된 예외 클래스의 인스턴스가 조건과 일치하는지를 판단합니다.
한 가지 유의할 점은, 예외가 발생하면 catch 블록은 위에서부터 순차적으로 검사를 진행하기 때문에, 구체적인 예외 클래스인 하위클래스를 먼저 위에 배치하여 상위 예외 클래스가 먼저 실행되지 않도록 방지하는 것이 좋습니다.
마치 우리가 자바 기초에서 조건문을 배울 때 구체적인 범위의 조건을 먼저 정의해 줬던 것과 같습니다.
(3) 두 번째 catch문
발생한 예외와 일치하는 조건이므로 해당 catch 문의 코드블록이 순차적으로 실행됩니다.
(4) 번에서 확인할 수 있는 것처럼 예외가 발생할 때 생성되는 예외 객체로부터 해당 에러에 대한 정보를 얻을 수 있는데, 크게 세 가지의 방법이 있습니다.
각각의 방법이 어떤 차이를 가지는지 좀 더 자세한 내용이 궁금하다면 구글링을 통해 알아보세요.
(4) finally 문
앞서 언급했던 것처럼 finally 문은 꼭 포함되어야 하는 문법은 아니지만, 만약에 포함이 되어있다면 예외 발생 여부와 관계없이 무조건 실행되게 됩니다.
예외 전가
try - catch 문 외에 예외를 호출한 곳으로 다시 예외를 떠넘기는 방법도 있다.
이를 위해서는 메서드의 선언부 끝에 아래와 같이 throws 키워드와 발생할 수 있는 예외들을 쉼표로 구분하여서 나열해 주면 된다.
반환타입 메서드명(매개변수, ...) throws 예외클래스1, 예외클래스2, ... {
...생략...
}
-------------------------------------------------------------------------------------
void ExampleMethod() throws Exception {
...생략...
}이 경우, Exception 클래스는 모든 예외 클래스의 상위 클래스이기 때문에 그 하위 클래스 타입의 예외 클래스들이 모두 포함되게 된다.
컬렉션 프레임 워크
컬렉션이란 여러 데이터의 집합을 의미한다. 즉, 여러 데이터를 그룹으로 묶어 놓은 것을 컬렉션이라고 하며, 이러한 컬렉션을 다루는데에 있어 편리한 메서드들을 미리 정의해 놓은 것을 컬렉션 프레임워크라고 한다.
컬렉션 프레임워크는 특정 자료구조에 데이터를 추가하고, 삭제하고, 수정하고, 검색하는 등의 동작을 수행하는 편리한 메서드들을 제공해 준다.

컬렉션 프레임워크는 주요 인터페이스로 List, Set, Map을 제공한다. 각각의 인터페이스를 요약하면 아래와 같다.
- List
- List는 데이터의 순서가 유지되며, 중복 저장이 가능한 컬렉션을 구현하는 데에 사용됩니다.
- ArrayList, Vector, Stack, LinkedList 등이 List 인터페이스를 구현합니다.
- Set
- Set은 데이터의 순서가 유지되지 않으며, 중복 저장이 불가능한 컬렉션을 구현하는 데에 사용됩니다.
- HashSet, TreeSet 등이 Set 인터페이스를 구현합니다.
- Map
- Map은 키(key)와 값(value)의 쌍으로 데이터를 저장하는 컬렉션을 구현하는 데에 사용됩니다.
- 데이터의 순서가 유지되지 않으며, 키는 값을 식별하기 위해 사용되므로 중복 저장이 불가능하지만, 값은 중복 저장이 가능합니다.
- HashMap, HashTable, TreeMap, Properties 등
이 셋 중에서 List와 Set은 서로 공통점이 많아 위 그림과 같이 Collection이라는 인터페이스로 묶인다. 즉, 이 둘의 공통점이 추출되어 추상화된 것이 바로 Collection이라는 인터페이스이다.
Collection 인터페이스
Collection 인터페이스에는 아래와 같은 메서드들이 정의되어 있다
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 |
boolean | add(Object o) / addAll(Collection c) |
주어진 객체 및 컬렉션의 객체들을 컬렉션에 추가합니다. |
| 객체 검색 |
boolean | contains(Object o) / containsAll(Collection c) |
주어진 객체 및 컬렉션이 저장되어 있는지를 리턴합니다. |
| Iterator | iterator() | 컬렉션의 iterator를 리턴합니다. | |
| boolean | equals(Object o) | 컬렉션이 동일한지 확인합니다. | |
| boolean | isEmpty() | 컬렉션이 비어있는지를 확인합니다. | |
| int | size() | 저장된 전체 객체 수를 리턴합니다. | |
| 객체 삭제 |
void | clear() | 컬렉션에 저장된 모든 객체를 삭제합니다. |
| boolean | remove(Object o) / removeAll(Collection c) |
주어진 객체 및 컬렉션을 삭제하고 성공 여부를 리턴합니다. | |
| boolean | retainAll(Collection c) | 주어진 컬렉션을 제외한 모든 객체를 컬렉션에서 삭제하고, 컬렉션에 변화가 있는지를 리턴합니다. | |
| 객체 변환 |
Object[] | toArray() | 컬렉션에 저장된 객체를 객체배열(Object [])로 반환합니다. |
| Object[] | toArray(Object[] a) | 주어진 배열에 컬렉션의 객체를 저장해서 반환합니다. |
List <E>
List
List 인터페이스는 배열과 같이 객체를 일렬로 늘어놓은 구조로 되어있다.
객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동으로 인덱스가 부여되고, 인덱스로 객체를 검색, 추가, 삭제할 수 있는 등의 여러 기능을 제공한다.
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | void | add(int index, Object element) | 주어진 인덱스에 객체를 추가 |
| boolean | addAll(int index, Collection c) | 주어진 인덱스에 컬렉션을 추가 | |
| Object | set(int index, Object element) | 주어진 위치에 객체를 저장 | |
| 객체 검색 | Object | get(int index) | 주어진 인덱스에 저장된 객체를 반환 |
| int | indexOf(Object o) / lastIndexOf(Object o) |
순방향 / 역방향으로 탐색하여 주어진 객체의 위치를 반환 | |
| ListIterator | listIterator() / listIterator(int index) |
List의 객체를 탐색할 수 있는 ListIterator 반환 / 주어진 index부터 탐색할 수 있는 ListIterator 반환 | |
| List | subList(int fromIndex, int toIndex) |
fromIndex부터 toIndex에 있는 객체를 반환 | |
| 객체 삭제 | Object | remove(int index) | 주어진 인덱스에 저장된 객체를 삭제하고 삭제된 객체를 반환 |
| boolean | remove(Object o) | 주어진 객체를 삭제 | |
| 객체 정렬 | void | sort(Comparator c) | 주어진 비교자(comparator)로 List를 정렬 |
List 인터페이스를 구현한 클래스로는 ArrayList, Vector, LinkedList, Stack 등이 있다.
이제 이중 가장 많이 사용되는 ArrayList와 LinkedList를 알아보자
ArrayList
ArrayList는 List 인터페이스를 구현한 클래스로, 컬렉션 프레임워크에서 가장 많이 사용된다.
기능적으로는 Vector와 동일하지만, 기존의 Vector를 개선한 것으로, Vector보다는 주로 ArrayList를 사용한다.
ArrayList에 객체를 추가하면 객체가 인덱스로 관리된다는 점에서는 배열과 유사하다.
그러나 배열은 생성될 때 크기가 고정되며, 크기를 변경할 수 없는 반면, ArrayList는 저장 용량을 초과하여 객체들이 추가되면, 자동으로 저장용량이 늘어나게 된다. 또한, 리스트 계열 자료구조의 특성을 이어받아 데이터가 연속적으로 존재한다. 즉, 데이터의 순서를 유지하게된다.
ArrayList를 생성하기 위해서는 저장할 객체 타입을 타입 매개변수, 즉 제네릭으로 표기하고 기본 생성자를 호출한다.
아래 코드예제를 확인해보자.
ArrayList<타입 매개변수> 객체명 = new ArrayList<타입 매개변수>(초기 저장 용량);
ArrayList<String> container1 = new ArrayList<String>();
// String 타입의 객체를 저장하는 ArrayList 생성
// 초기 용량이 인자로 전달되지 않으면 기본적으로 10으로 지정됩니다.
ArrayList<String> container2 = new ArrayList<String>(30);
// String 타입의 객체를 저장하는 ArrayList 생성
// 초기 용량을 30으로 지정하였습니다.ArrayList에 객체를 추가하면 인덱스 0부터 차례대로 저장된다. 그리고 특정 인덱스의 객체를 제거하면, 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 1씩 당겨진다.
따라서 빈번한 객체 삭제와 삽입이 일어나는 곳에서는 ArrayList보다 이후에 나오는 LinkedList를 사용하는 것이 좋다.
다음은 ArrayList에 String 객체를 추가, 검색, 삭제하는 코드예제를 확인해보자.
public class ArrayListExample {
public static void main(String[] args) {
// ArrayList를 생성하여 list에 할당
ArrayList<String> list = new ArrayList<String>();
// String 타입의 데이터를 ArrayList에 추가
list.add("Java");
list.add("egg");
list.add("tree");
// 저장된 총 객체 수 얻기
int size = list.size();
// 0번 인덱스의 객체 얻기
String skill = list.get(0);
// 저장된 총 객체 수 만큼 조회
for(int i = 0; i < list.size(); i++){
String str = list.get(i);
System.out.println(i + ":" + str);
}
// for-each문으로 순회
for (String str: list) {
System.out.println(str);
}
// 0번 인덱스 객체 삭제
list.remove(0);
}
}
LinkedList
LinkedList 컬렉션은 데이터를 효율적으로 추가, 삭제, 변경하기 위해 사용한다.
배열에는 모든 데이터가 연속적으로 존재하지만, LinkedList에는 불연속적으로 존재하며, 이 데이터는 서로 연결(link)되어 있다.

그림을 통해 알 수 있듯이, LinkedList의 각 요소(node)들은 자신과 연결된 이전 요소 및 다음 요소의 주소값과 데이터로 구성되어 있다.
LinkedList에서 데이터를 삭제하려면, 삭제하고자 하는 요소의 이전 요소가 삭제하고자 하는 요소의 다음 요소를 참조하도록 변경하면 된다. 링크를 끊어주는 방식이라고 생각하면 된다.
배열처럼 데이터를 이동하기 위해 복사할 필요가 없기 때문에 처리 속도가 훨씬 빠르다.
데이터를 추가할 때도 마찬가지로, 새로운 요소를 추가하고자 하는 위치의 이전 요소와 다음 요소 사이에 연결해 주면 된다. 즉, 이전 요소가 새로운 요소를 참조하고, 새로운 요소가 다음 요소를 참조하게 만드는 것이다.
LinkedList를 활용한 예제를 확인해보자.
public class LinkedListExample {
public static void main(String[] args) {
// Linked List를 생성하여 list에 할당
LinkedList<String> list = new LinkedList<>();
// String 타입의 데이터를 LinkedList에 추가
list.add("Java");
list.add("egg");
list.add("tree");
// 저장된 총 객체 수 얻기
int size = list.size();
// 0번 인덱스의 객체 얻기
String skill = list.get(0);
// 저장된 총 객체 수 만큼 조회
for(int i = 0; i < list.size(); i++){
String str = list.get(i);
System.out.println(i + ":" + str);
}
// for-each문으로 순회
for (String str: list) {
System.out.println(str);
}
// 0번 인덱스 객체 삭제
list.remove(0);
}
}
ArrayList와 LinkedList 차이
ArrayList의 특성
- 데이터를 추가 또는 삭제를 하려면 다른 데이터를 복사해서 이동해야 한다.
- 객체를 순차적으로 저장할 때는 데이터를 이동하지 않아도 되므로 작업 속도가 빠르다
- 중간에 위치한 객체를 추가 및 삭제할 때는 데이터 이동이 많이 일어나므로 속도가 저하된다.
- 인덱스가 n인 요소의 주소값을 얻기 위해서는 배열의 주소 + n * 데이터 타입의 크기를 계산하여 데이터에 빠르게 접근이 가능하기 때문에 검색(읽기) 측면에서는 유리하다.
ArrayList는 다음과 같은 상황에 강점을 지닌다.
- 데이터를 순차적으로 추가하거나 삭제하는 경우
- 순차적으로 추가한다는 것은 0번 인덱스에서부터 데이터를 추가하는 것을 의미합니다.
- 순차적으로 삭제한다는 것은 마지막 인덱스에서부터 데이터를 삭제하는 것을 의미합니다.
- 데이터를 불러오는 경우
- 인덱스를 통해 바로 데이터에 접근할 수 있으므로 검색이 빠릅니다.
ArrayList는 다음과 같은 상황에 효율적이지 못하다.
- 중간에 데이터를 추가하거나, 중간에 위치하는 데이터를 삭제하는 경우
- 추가 또는 삭제 시, 해당 데이터의 뒤에 위치한 값들을 뒤로 밀어주거나 앞으로 당겨주어야 합니다.
LinkedList의 특성
- LinkedList의 중간에 데이터를 추가하면, Next와 Prev에 저장되어 있는 주소값만 변경해 주면 되므로, 각 요소를 ArrayList처럼 뒤로 밀어내지 않아도 된다
- 중간에 위치한 데이터를 삭제하는 경우에도 삭제한 데이터의 뒤에 위치하는 요소들을 앞으로 당기지 않아도 된다.
- 데이터를 중간에 추가하거나 삭제하는 경우, LinkedList는 ArrayList보다 빠른 속도를 보여줍니다.
- 데이터 검색할 때는 시작 인덱스에서부터 찾고자 하는 데이터까지 순차적으로 각 노드에 접근해야 하므로 데이터 검색에 있어서는 ArrayList보다 상대적으로 속도가 느립니다.
LinkedList는 다음과 같은 상황에 강점을 가진다.
- 중간에 위치하는 데이터를 추가하거나 삭제하는 경우
- 데이터를 중간에 추가하는 경우, Prev와 Next의 주소값만 변경하면 되므로, 다른 요소들을 이동시킬 필요가 없다.
데이터의 잦은 변경이 예상되는 상황에서는 LinkedList를, 데이터의 개수가 변하지 않는 상황에서는 ArrayList를 사용하는 것이 좋다.
Iterator
자바 컬렉션에서 Iterator 는 컬렉션에 저장된 요소들을 순차적으로 읽어오는 역할을 한다.
이러한 Iterator의 컬렉션 순회 기능은 Iterator 인터페이스에 정의되어 있으며, Collection 인터페이스에는 Iterator인터페이스를 구현한 클래스의 인스턴스를 반환하는 메서드인 iterator() 가 정의되어 있다.
Collection 인터페이스에 정의된 iterator()를 호출하면, Iterator 타입의 인스턴스가 반환된다.
따라서 Collection 인터페이스를 상속받는 List와 Set 인터페이스를 구현한 클래스들은 iterator() 메서드를 사용할 수 있다.
다음은 Iterator 인터페이스에 정의된 메서드로, iterator()를 통해 만들어진 인스턴스는 아래의 메서드를 사용할 수 있다.
| 메서드 | 설명 |
| hasNext() | 읽어올 객체가 남아 있으면 true를 리턴하고, 없으면 false를 리턴합니다. |
| next() | 컬렉션에서 하나의 객체를 읽어옵니다. 이때, next()를 호출하기 전에 hasNext()를 통해 읽어올 다음 요소가 있는지 먼저 확인해야 합니다. |
| remove() | next()를 통해 읽어온 객체를 삭제합니다. next()를 호출한 다음에 remove()를 호출해야 합니다. |
Iterator를 활용하여 컬렉션의 객체를 읽어올 때는 next() 메서드를 사용한다. next() 메서드를 사용하기 전에는 먼저 가져올 객체가 있는지 hasNext() 를 통해 확인하는 것이 좋다.
hasNext() 메서드는 읽어올 다음 객체가 있으면, true를 리턴하고, 더 이상 가져올 객체가 없으면 false를 리턴한다. 따라서 true가 리턴될 때만 next() 메서드가 동작하도록 코드를 작성해야 한다.
아래 코드 예제는 List 에서 String 객체들을 반복해서 하나씩 가져오는 예제다
ArrayList<String> list = ...;
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) { // 읽어올 다음 객체가 있다면
String str = iterator.next(); // next()를 통해 다음 객체를 읽어옵니다.
...
}Iterator를 사용하지 않더라도, for-each문을 이용해서 전체 객체를 대상으로 반복할 수 있다.
ArrayList<String> list = ...;
for(String str : list) {
...
}next() 메서드로 가져온 객체를 컬렉션에서 제거하고 싶다면 remove() 메서드를 호출하면 된다.
next() 메서드는 컬렉션의 객체를 그저 읽어오는 메서드로, 실제 컬렉션에서 객체를 빼내는 것은 아니다. 하지만, remove()메서드는 컬렉션에서 실제로 객체를 삭제한다.
ArrayList<String> list = ...;
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){ // 다음 객체가 있다면
String str = iterator.next(); // 객체를 읽어오고,
if(str.equals("str과 같은 단어")){ // 조건에 부합한다면
iterator.remove(); // 해당 객체를 컬렉션에서 제거합니다.
}
}
Set
자바 컬렉션에서 Set은 요소의 중복을 허용하지 않고, 저장 순서를 유지하지 않는 컬렉션이다.
대표적인 Set을 구현한 클래스에는 HashSet, TreeSet이 있다.
Set 인터페이스에 정의된 메서드들은 다음과 같다.
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | boolean | add(Object o) | 주어진 객체를 추가하고, 성공하면 true를, 중복 객체면 false를 반환합니다. |
| 객체 검색 | boolean | contains(Object o) | 주어진 객체가 Set에 존재하는지 확인합니다. |
| boolean | isEmpty() | Set이 비어있는지 확인합니다. | |
| Iterator | Iterator() | 저장된 객체를 하나씩 읽어오는 반복자를 리턴합니다. | |
| int | size() | 저장된 전체 객체의 수를 리턴합니다. | |
| 객체 삭제 | void | clear() | Set에 저장된 모든 객체를 삭제합니다. |
| boolean | remove(Object o) | 주어진 객체를 삭제합니다. |
HashSet
HashSet은 Set 인터페이스를 구현한 가장 대표적인 컬렉션 클래스이다. 따라서, Set 인터페이스의 특성을 그대로 물려받으므로 중복된 값을 허용하지않으며, 저장 순서를 유지하지 않는다.
HashSet에 값을 추가할 때, 어떻게 해당 값이 중복된 값인지 판단할까? 그 과정을 간단하게 설명하면 아래와 같다.
- add(Object o)를 통해 객체를 저장하고자 합니다.
- 이때, 저장하고자 하는 객체의 해시코드를 hashCode() 메서드를 통해 얻어냅니다.
- Set이 저장하고 있는 모든 객체의 해시코드를 hashCode() 메서드로 얻어냅니다.
- 저장하고자 하는 객체의 해시코드와, Set에 이미 저장되어 있던 객체들의 해시코드를 비교하여, 같은 해시코드가 있는지 검사합니다.
- 이때, 만약 같은 해시코드를 가진 객체가 존재한다면 아래의 5번으로 넘어갑니다.
- 같은 해시코드를 가진 객체가 존재하지 않는다면, Set에 객체가 추가되며 add(Object o) 메서드가 true를 리턴합니다.
- equals() 메서드를 통해 객체를 비교합니다.
- true가 리턴된다면 중복 객체로 간주하여 Set에 추가되지 않으며, add(Object o)가 false를 리턴합니다.
- false가 리턴된다면 Set에 객체가 추가되며, add(Object o) 메서드가 true를 리턴합니다.
Set을 활용하는 간단한 예제를 살펴보자.
import java.util.*;
public class Main {
public static void main(String[] args) {
// HashSet 생성
HashSet<String > languages = new HashSet<String>();
// HashSet에 객체 추가
languages.add("Java");
languages.add("Python");
languages.add("Javascript");
languages.add("C++");
languages.add("Kotlin");
languages.add("Ruby");
languages.add("Java"); // 중복
// 반복자 생성하여 it에 할당
Iterator it = languages.iterator();
// 반복자를 통해 HashSet을 순회하며 각 요소들을 출력
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
// 출력값
Java
C++
Javascript
Ruby
Python
Kotlin입력한 순서대로 출려되지 않고, "Java"를 두 번 추가했지만 한 번만 저장된 것을 확인할 수 있다.
TreeSet
TreeSet은 이진 탐색 트리 형태로 데이터를 저장한다. 데이터의 중복 저장을 허용하지 않고 저장 순서를 유지하지 않는 Set 인터페이스의 특징은 그대로 유지된다.
여기서 이진 탐색 트리(Binary Search Tree)란 하나의 부모 노드가 최대 두 개의 자식 노드와 연결되는 이진트리(Binary Tree)의 일종으로, 정렬과 검색에 특화된 자료 구조이다.
이때 최상위 노드를 ‘루트'라고 한다. 아래 그림에서 10이 바로 루트 노드에 해당한다.
이진 탐색 트리는 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가지는 특징이 있다.

이러한 자료 구조를 구현하기 위한 의사 코드는 다음과 같습니다. 위 그림의 각 노드들은 아래 Node 클래스를 인스턴스화한 인스턴스에 해당한다.
class Node {
Object element; // 객체의 주소값을 저장하는 참조변수 입니다.
Node left; // 왼쪽 자식 노드의 주소값을 저장하는 참조변수입니다.
Node right; // 오른쪽 자식 노드의 주소값을 저장하는 참조변수입니다.
}
TreeSet을 활용한 코드 예제를 확인해보자
import java.util.TreeSet;
public class TreeSetExample {
public static void main(String[] args) {
// TreeSet 생성
TreeSet<String> workers = new TreeSet<>();
// TreeSet에 요소 추가
workers.add("Lee Java");
workers.add("Park Hacker");
workers.add("Kim Coding");
System.out.println(workers);
System.out.println(workers.first());
System.out.println(workers.last());
System.out.println(workers.higher("Lee"));
System.out.println(workers.subSet("Kim", "Park"));
}
}
// 출력값
[Kim Coding, Lee Java, Park Hacker]
Kim Coding
Park Hacker
Lee Java
[Kim Coding, Lee Java]출력값을 확인해 보면, 요소를 추가하기만 했음에도 불구하고, 자동으로 사전 편찬 순에 따라 오름차순으로 정렬된 것을 확인할 수 있다. 이는 TreeSet의 기본 정렬 방식이 오름차순이기 때문이다.
Map<K, V>
Map
Map 인터페이스는 키(key)와 값(value)으로 구성된 객체를 저장하는 구조로 되어 있다. 여기서 이 객체를 Entry 객체라고 하는데, 이 Entry 객체는 키와 값을 각각 Key 객체와 Value 객체로 저장한다.
Map을 사용할 때 중요한 사실은 키는 중복으로 저장될 수 없지만, 값은 중복 저장이 가능하다는 것이다. 이는 키의 역할이 값을 식별하는 것이기 때문이다.
만약 기존에 저장된 키와 같은 키로 값을 저장하면, 기존의 값이 새로운 값으로 대치된다.
Map 인터페이스를 구현한 클래스에는 HashMap, Hashtable, TreeMap, SortedMap 등이 있다.
다음은 Map 인터페이스를 구현한 클래스에서 공통으로 사용할 수 있는 메서드입니다. List가 인덱스를 기준으로 관리되는 반면에, Map은 키(key)로 객체들을 관리하기 때문에 키를 매개값으로 갖는 메서드가 많다.
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | Object | put(Object key, Object value) |
주어진 키로 값을 저장합니다. 해당 키가 새로운 키일 경우 null을 리턴하지만, 같은 키가 있으면 기존의 값을 대체하고 대체되기 이전의 값을 리턴합니다. |
| 객체 검색 | boolean | containsKey (Object key) |
주어진 키가 있으면 true, 없으면 false를 리턴합니다. |
| boolean | containsValue (Object value) |
주어진 값이 있으면 true, 없으면 false를 리턴합니다. | |
| Set | entrySet() | 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴합니다. | |
| Object | get(Object key) | 주어진 키에 해당하는 값을 리턴합니다. | |
| boolean | isEmpty() | 컬렉션이 비어 있는지 확인합니다. | |
| Set | keySet() | 모든 키를 Set 객체에 담아서 리턴합니다. | |
| int | size() | 저장된 Entry 객체의 총 갯수를 리턴합니다. | |
| Collection | values() | 저장된 모든 값을 Collection에 담아서 리턴합니다. | |
| 객체 삭제 | void | clear() | 모든 Map.Entry(키와 값)을 삭제합니다. |
| Object | remove(Object key) | 주어진 키와 일치하는 Map.Entry를 삭제하고 값을 리턴합니다. |
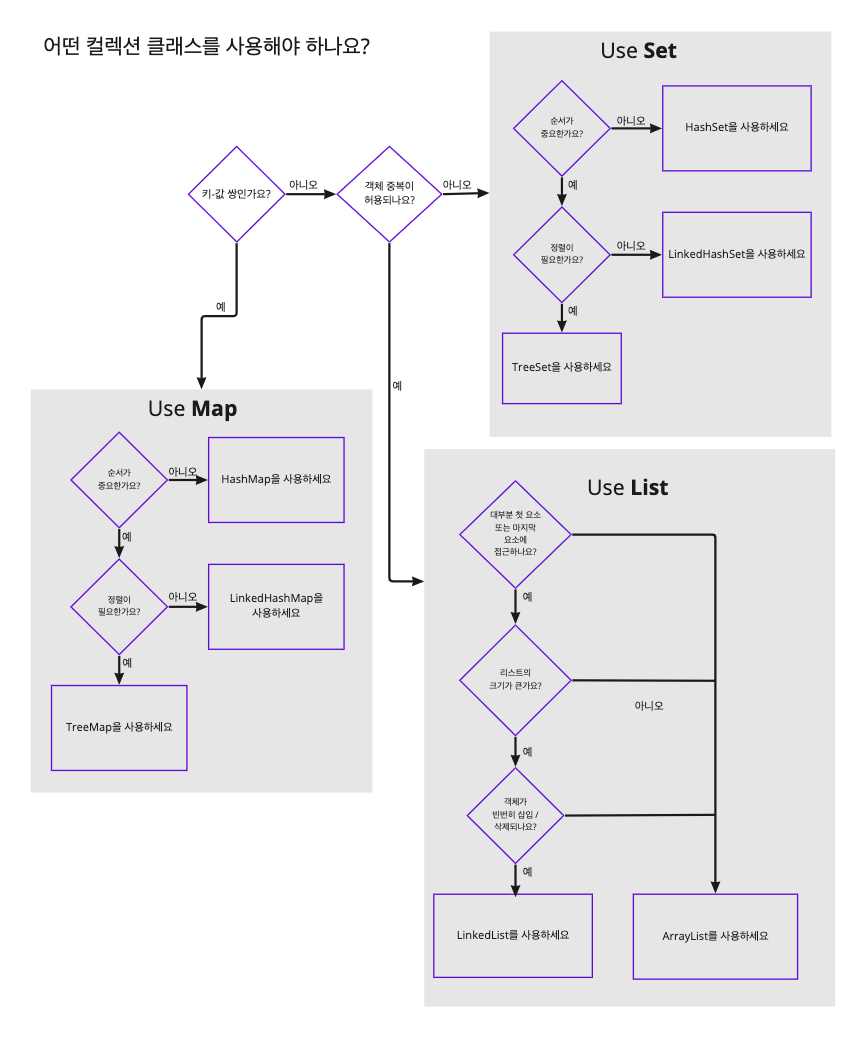
아래의 이미지를 통해 어떤 상황에서 어떤 컬렉션 클래스를 써야 하는지 공부하자
'코드 스테이츠' 카테고리의 다른 글
| 코드스테이츠 - Java 심화 (Effective)2 (0) | 2023.05.04 |
|---|---|
| 코드 스테이츠 - Java 심화(Effective) 1 (0) | 2023.05.03 |
| 코드 스테이츠 4/26 - 객체지향 프로그래밍 심화 2 (0) | 2023.04.26 |
| 코드 스테이츠 04/25 - 객체 지향 프로그래밍 심화1 (1) | 2023.04.25 |
| 코드 스테이츠 4/24 - 객체지향 프로그래밍 기초 2 (0) | 2023.04.24 |



